RecSys 2023 overview
Detailed overview of the 17th ACM Conference on Recommender Systems (RecSys 2023), including the general feel of the conference, research trends, top5 papers & other conference highlights.

The 17th ACM Conference on Recommender Systems - or RecSys 2023 for short - was held in Singapore between September 18-22. This was the 9th RecSys I attended (and the 14th I followed). After a few years of hiatus, I started publishing papers again, so I also had two papers to present.
This year the conference started to shift towards being an in-person only event. While it was possible for the audience to join remotely, presenters had to be there in-person. This is not necessarily a bad thing, because it minimizes technical glitches - although we hardly had any in the last two years - but it further limits the engagement of the remote audience, since discussions move more into the offline world.
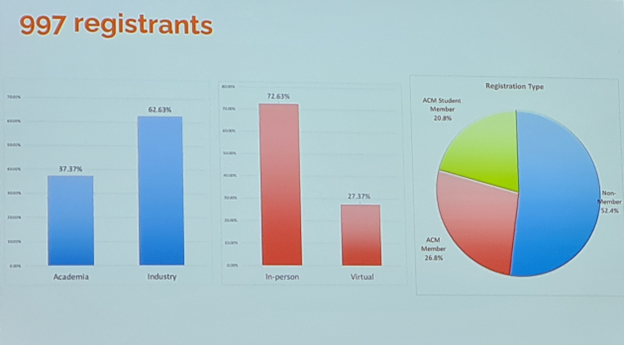
The conference is still popular in the industry. Approximately two thirds of the audience comes from the industry. Major players of this space represented themselves with sizable contingents. Many mid and small size companies also sent their research scientists and engineers to the conference as it can greatly benefit them. No statistics were published on how much of the contributions come from the industry, but I have a feeling that it is above 50%.
Contributions could be submitted to the usual tracks: research papers (long and short), reproducibility papers (long and short), industry presentations, late breaking results and demos. The research track is mostly for novel solutions, and occasionally studies analyzing some aspect of recommenders. This is the most popular track by far. The reproducibility track focuses on the state of reproducibility in recsys research, evaluation in general, obstacles in the way of reproducing research and attempts at reproducing the results of certain papers. As the evaluation crisis (see below) deepens, this track is becoming more and more prominent. Industry presentations are more focused around how a certain company that works in a certain domain and faces a specific problem solves it using (mostly) already available techniques. Scientific novelty is less important here, so companies usually target this track with their more engineering heavy works, while also submitting their research results to the research track.
This year the conference received double the submissions of last year. The organizers decided to keep the ~20% acceptance rate, thus the conference ended up with a record number of works to present: 47 long research, 48 short research, 7 reproducibility, 30 industry, 19 late breaking result, 6 demo and 15 doctoral symposium papers. Fitting all of this into the three main conference days is not an easy task, so the organizers decided to go for two parallel sessions that mix long research and reproducibility papers, as well as selected industry papers. The rest were presented as posters during the daily poster sessions.
I like the idea of mixed (research, reproducibility, industry) sessions, but I’m in two minds about parallel sessions. Parallel sessions mean that I can only experience a part of the conference and the pairing is usually done in a way that either I’d attend both sessions at once or I’m not interested in either. On the other hand, if there is a lot of high quality work to be presented, it is better to have them in parallel than to not have some of the work at all due to limited presentation slots. (Of course, I often feel that half of the presentations could have been scrapped to give space for the other half, but in reality the program would never be the half I’d want it to be, even if the organizers decided to lower the acceptance rate.) Kudos to the presenters and session chairs for making sure that none of the presentations ran out of the allocated 15+5 minutes that made session hopping possible. With this, I think that having parallel sessions was the right call.
The poster sessions also went well. The posters were set up in the conference hall, so anyone going out of the presentation rooms could find them easily. There was enough space, it never felt overcrowded. I also think that dividing up poster presentations between the three days was a good idea, because this gave everyone enough time to look at all of the posters and presenters had the time to talk about their work with those who were interested.
The one criticism I have for this year is that the AV support wasn’t as great as the last two years. For example, presenters had to load their own slides that were stored on a shared computer that didn’t even have a proper pdf reader; and since no instructions were given beforehand, this surprised many of us and resulted in a few tens of seconds (sometimes up to a minute) of figuring out where it is and how to make it full screen.
State of the research
The general state of the research is fairly similar to that of the last few years. Algorithmic papers are dominated by deep neural networks, similarly to almost every domain that builds on machine learning. There was no breakthrough solving any of the long standing problems of recommenders. Popular topics are more or less the same as in previous years. The community seemingly puts more emphasis on discussing evaluation, as more people realize that we have an evaluation crisis on our hands. This year’s newcomer topic - unsurprisingly - is focused on utilizing LLMs for recommendations.
Established trends

Maybe my session selection was very biased, but to me the submission topic distribution seems more representative of the conference than the topic distribution of accepted papers. Sequential recommendations are still very popular as they have been in the last few years. On one hand I’m happy about this, because the revitalization of the area can be - in large part - attributed to GRU4Rec. On the other hand, most of the research conducted in this area is very incremental with limited practical use. But an even bigger problem is that due to deeply flawed evaluation setups utilized by the majority of the papers, the lack of proper baseline optimization and imperfect baseline implementations, the results presented in these papers are meaningless more often than not. Other popular topics include graph neural networks, CTR prediction, bias/debiasing and fairness.
Cutting-edge research
While the conference had a session on reinforcement learning, I was surprised how marginal reinforcement learning was this year. Even though several people expressed that they will need reinforcement learning to move forward, it also seemed to me that the research of thus topic hit a wall.
The other topic I beleive to be the future of recommenders is counterfactual evaluation (and learning). This was almost completely missing from the main conference, but luckily the CONSEQUENCES workshop focused on this topic. What I see here is that despite years of progress, counterfactual learning is still (mostly) in the lab, as they don’t seem to work with action spaces of real-life recommender systems and thus we are still in the phase of using small scale simulated data. There have been a few papers in the past that suggested production adjacent use, but usually there is no follow-up on these and no confirmation by others whether they have found these methods useful or not. Recent work mostly cites the better known IPS (CIPS, SNIPS, etc.) and DR techniques and reuses these ideas in different setups (e.g. ranking). Nevertheless, I still expect a lot from this research direction in the future.
New directions
A new topic that probably surprises no one is the use of “Generative AI” in recommenders. While generative models for recommendations have been around for more than a decade, this research direction focuses on utilizing pretrained generative models. For now, the focus is mostly on large language models (LLMs). I was actually surprised that the conference wasn’t flooded with LLM papers. This is a good thing, because many of the papers that focus on the actual hype are known to have low quality. The LLM papers I saw at the conference were reasonable. While it seems that the industry is excited about utilizing these models in some form, engineers also see that this is not a trivial task. LLMs might help or extend recommenders, the initial idea of using them directly to recommend items won’t be feasible mid-term.
Another topic that was not represented in many papers, but came up a few times during discussions is A/B testing and asking whether treating A/B test results as the gold standard is a good idea. It is well known that doing proper A/B tests is not trivial. It is less well known that many of the KPIs that we can measure well in A/B tests are only proxies of business or system goals. But more recently, the reliability of A/B testing in complex systems also into question. For example, how much can a simple model “steal” from a well generalizing model through the training data when the two are in an A/B test and how much this affects results.
Evaluation crisis
Evaluation has been a central question of recsys research ever since we moved from the mathematically exact, but practically meaningless rating prediction task to top-N recommendations more than a decade ago. There were times where it was more in the focus and there were times when it was in the background, but it never really disappeared. And it was never really solved.
The major points of these discussions have traditionally focused on finding connection between offline evaluation and the online world, i.e. do our offline metrics even mean anything. This includes well-known topics such as: offline metrics are just proxies, feedback loop affects evaluation, metrics beyond accuracy, etc. But more recently, another problem cropped up its head and in my opinion this is a much more serious issue than online-offline discrepancy. I think that it can undermine our research domain as a whole.
This problem is the low quality of empirical evaluation and baseline comparisons in recommender systems papers. It includes flawed/uninformative evaluation setups, faulty baseline implementations, badly parameterized baselines, flatout unfair comparisons, etc. This problem is not specific to recommender systems, but given the already obscure interpretability of offline results, it is a much more serious problem than in other fields, where offline evaluation is clear and the results are “absolute”. This problem is also not a new one, it probably has been around since the early days. But it is inflated by the explosion in the number of papers written and published. In this environment, if a paper gets popular, there is a high chance that many others will simply copy its evaluation methodology, even if it is flawed. Some of these are bound to be accepted even to good conferences at some point as they only need to slip through reviewers once. Due to the high number of submissions, conferences are desperate for reviewers, so if someone has already published a paper at a conference, they are likely invited as a reviewer next year, further lowering the bar in front of papers with low quality evaluation.
Take sequential recommendations as an example. As the author of GRU4Rec, I’m often asked to review papers in this area. I distinctly remember the harsh review I gave to a journal paper in 2017 that evaluated its overcomplicated algorithm on the Netflix rating dataset, where the timestamp has a daily resolution so the original order of a user’s events on the same day can’t be determined. Not to mention that not every dataset is appropriate to model a sequential recommendation problem, the data might not even have sequential patterns at all. Fast forward 6 years and most of the papers in this area use non-sequential data; not the Netflix data, but it’s the same problem. Even the majority presented at RecSys 2023, the premiere conference on recommendations. This can be traced back to a few papers that started using these flawed setups, even though they could have relied on earlier work with decent evaluation. There were many such papers, some of them slipped through the reviewers and a few of them became popular. The dataset used is not the only issue. Negative sampling during evaluation has been used for many years without any real justification just to save time for running experiments with poorly optimized code and unscalable methods. Past the evaluation setup itself, it is clearly apparent from disclosed results that baselines are either not optimized properly or their implementations are faulty, but probably both.
In a research area, where offline results are imperfect proxies and their real-life effects are up to interpretation, this can have dire consequences. I’m already at the point where I don’t really consider the evaluation section of papers I read if I’m not reviewing. Instead, I assess the merit of a paper based on subjective criteria: how much do I like the idea, do I think that it is something that could work, etc. Many people I met at the conference shared this sentiment. But this is bad. Yes, the more experienced you are, the better you are at identifing good methods. But you will still make errors and miss good methods and waste your time with bad ones. If you are in the industry, you can just implement what you think is promising and measure performance online, and eliminate the uncertainty around a paper’s merit. But you still need to do a subjective prefiltering, due to finite time and resources. Also, by relying only on your own online results, you distance yourself from the community and those who don’t have access to your proprietary system, effectively losing the advantage of knowledge sharing: you won’t consider anyone else’s results valid because it was not done in your system and others won’t consider your results valid, because they have no idea what is going on in there. The result is a lot of unnecessary parallel work done in separated silos without a clear general understanding of what really works and under what conditions.
While more and more people start to realize the problem and there are a few initiatives to somewhat alleviate it (e.g. reproducibility track), it is nowhere near enough. Unfortunately, I also can’t offer a simple solution that can be executed easily. Educating the community is an important component of the solution in the long run. In the short/mid term, educating and overseeing reviewers is what could probably have the biggest impact. Another part of the solution would be to stop rushing. I know that it is not easy, especially if someone is under pressure to publish. But based on the conversations I had with people, these flawed setups are not motivated by malice, they are motivated by the lack of time. In a hurry it is faster to use Movielens for evaluating anything from CTR prediction to sequential recommenders than looking for an appropriate dataset. It is faster to compare against 100 negative samples than to write fast code. It is faster to use a random reimplementation in a familiar framework than to install a different environment and understand code in a different framework. It is faster to use the default hyperparameters or values reported by a third-party (usually on a different dataset or split or evaluation setup) than to do hyperparameter search. Yes, doing all of this properly will slow down publication output, but at least the work might have some impact.
Our contributions
After a few years of hiatus, this year we submitted two papers to RecSys and both of them were accepted for presentation at the conference. Our work this year closely connects to the evaluation crisis. In fact, one of the main motivations was to raise awareness to those aspects of this problem that have been neglected by the community so far.
The Effect of Third Party Implementations on Reproducibility
This paper was submitted to the reproducibility track, which focuses on reproducing earlier research and discussing the problems preventing us to do so. We looked at a previously unexplored aspect of reproducibility: reimplementations. Reimplementing an algorithm is not a new practice, researchers implementing their baselines used to be common practice before open sourcing research code became widespread. The correctness of these private reimplementations was always one of the uncertainties around the believability of baseline comparisons. Unfortunately, these couldn’t be validated due to their private nature. One of the proposed solutions was to build and then use benchmarking frameworks that (currently) are algorithm collections with a shared evaluator on the top of them. More recently, standalone public reimplementations of well-known algorithms have also appeared. There are many valid reasons for reimplementing an algorithm, such as making it available in a different programming language or deep learning framework, ease of use, modifications required for new types of experiments, optimizing training/inference times, etc. The question is whether the reimplementations are correct representations of the original.
Checking every implementation of every algorithm is not feasible, so we chose GRU4Rec and compared six of its reimplementations (two in PyTorch, two in Tensorflow and two in benchmarking frameworks) to the original. Beside knowing GRU4Rec well, choosing it makes sense for multiple reasons: (1) It has a simple architecture that is not hard to replicate. (2) But it is not a direct application of GRU. It is adapted to the recommendation domain and it has distinct features. Therefore, reimplementing it requires paying attention to the papers describing it. (3) It is a seminal work for session-based/sequential algorithms. (4) It is implemented in Theano, a deep learning framework that is no longer supported by its developers. Even though it still works fine on recent hardware and software environments, it provides motivation for reimplementation. (5) It has an official open source implementation that reimplementation can base themselves on or validate against.
We asked five research questions:
- Do reimplementations implement the same architecture as the original?
- Do reimplementations contain all distinctive features of the original?
- Do reimplementations have any implementation errors? Implementation errors are defined as either incorrect/buggy implementation of some part of the algorithm or deviating from the original.
- Is there any loss in recommendation accuracy due to missing features or implementation errors?
- How do the training times of the reimplementations compare to that of the original?
And got the following worrying answers:
- Five of six do. The Microsoft Recommenders version does something entirely different, which is also deeply flawed as it is not able to rank more than a few tens of items. Therefore this version is excluded from the other experiments.
- No, none of the implementations are feature complete.
- Yes, all of the reimplementations have implementation errors ranging from typos and easily detectable and fixable errors to core errors that can’t be fixed without rewriting the code almost from scratch.
- Yes, the accuracy loss is quite significant. Measured on five datasets, the median degradation is between -7.5% and -89.5% depending on which implementation we are talking about. The maximum degradation is between -27.2% and -99.6%.
- They are significantly slower, especially the ones that don’t do negative sampling. In the most extreme case, the reimplementation took 336 times more time to train than the original (approximately 40 hours per epoch on an A30 GPU).
The idea of examining this topic has been in my head for years, ever since I saw implementations of GRU4Rec popping up along with unrealistically bad results. I had a hunch that some of the reimplementation wouldn’t be correct, but I didn’t expect the situation to be this bad. At first, I didn’t think that this would become a publication, but as we delved more into the details, I realized that this is a serious problem that potentially affects many algorithms and a vast part of the literature. GRU4Rec is a relatively simple algorithm with an official open source implementation that enables the validation of the reimplementation and serves as a good starting point. If the reimplementations of such an algorithm are flawed, how likely is it that more complex or closed source algorithms are reimplemented correctly?
As a consequence of our findings, a lot of research results from the last few years are probably invalid. The best course of action would be rerunning experiments using correct implementations that have been validated against their original counterpart. But I’m skeptical that this will happen. In the future, authors should make it clear which implementation they use to avoid confusion and reviewers should raise questions if a not a validated version is used. Meanwhile, existing and future reimplementations (including ones in benchmarking framework) must be validated and the validation process and its results must be described in detail. The research community mustn’t trust any reimplementation that hasn’t been validated, even if it is in a benchmarking framework.
It is ironic that a few months after we started this work, the CFP for RecSys 2023 came out and it advised authors to use benchmarking frameworks to ensure reproducibility and provided a list of “verified” frameworks. (Sidenote: I wonder who verified these frameworks and how.) The list contains two frameworks we checked and another one that we checked after the paper was submitted (which also has an incorrect reimplementation of GRU4Rec). This highlights an important problem that contributes to the evaluation crisis. If tools are popularized first and validated later, our good intentions might work against reproducibility and not for it. I wonder if this list will be in next year’s CFP, and if so, will the algorithms of these frameworks - all algorithms, not just GRU4Rec - be validated against their official counterparts or their original paper? I’m not against benchmarking frameworks - even though I think we are approaching them from the wrong direction - but before pushing them into the spotlight, we should make sure that they help reproducibility of research and not hinder it.

The paper was presented as an oral presentation during the first regular session of the conference. The audience was highly engaged with the topic, I got a lot of follow-up questions after the presentation. Several people (both academia & industry) also came up to me in person and praised this work for its thoroughness and for raising awareness about this problem. I was also approached by two groups who had their own implementations (not the ones discussed in the paper) asking for advice on how to fix certain things in their work. Several people were also happy that I released official implementations in PyTorch and Tensorflow. Since then, I was also contacted by the author of one of the reimplementations who wrote a good disclaimer for his version directing people towards the official versions. Overall, I could say that the paper was received positively.
Widespread Flaws in Offline Evaluation of Recommender Systems
Our second paper focused on a different aspect of the evaluation crisis: the evaluation setup. It is well known that offline evaluation is just an imperfect proxy of online results (which is often also a proxy of business/recommender goals). Therefore it is of utmost importance that offline evaluation setups are as realistic as they can be. (Sidenote: being aware of the limitations of a given setup and understanding what results achieved under a given setup mean are also super important.)
Unfortunately, unrealistic evaluation setups have been around for more than a decade. With the quickly increasing paper output (and thus decreasing median quality of published papers) in the last five-six years, these became much more widespread. For example, in the case of sequential/session-based recommendations, a few papers around 2018 started to deviate from the decent evaluation setup used in prior work (without any justification), and their flawed evaluation setup started to spread through the field. The problem is that using a flawed evaluation setup makes the empirical evaluation of any proposed method totally uninformative. The proposed algorithm might be still good or it might be bad, but we will have no idea based on the results of a flawed evaluation.
In this paper, we described the process of designing an evaluation setup from defining the task, selecting appropriate methodology and metrics to processing and splitting the data and finally measuring recommendation accuracy. We highlighted four common flaws related to some of the steps of this process and explained why researchers should avoid making these mistakes.
- One dataset fits all mentality, using datasets that are inappropriate for the task. E.g. using data with no sequential patterns for evaluating sequential recommenders. Or using rating data for evaluating CTR prediction.
- Making general claims on heavily preprocessed datasets. E.g. claiming that the proposed algorithm is the new state-of-the-art (in general) after evaluating on a dataset where half of the users were removed due to heavy support filtering.
- Using non time based train/test splits, which allow for information leaking through time and lower the difficulty of the test set by reducing the effect of natural concept drift. E.g. the commonly used leave-one-out approach, where the last event of every sequence is the target, and these fall into a timeframe that overlaps with the training set.
- Negative sampling during training, which is mostly used to compensate for poorly optimized code or unscalable methods by only ranking the target item(s) against a handful of positives. This both significantly overestimates the performance of the algorithm, since even carefully selected negatives are likely to be weak negatives; and it often changes the relative performance of different algorithms.
The paper was submitted to the research track as a short paper and was presented as a poster on the second day of the conference. Many people visited our poster and we felt that they were highly engaged. We got very nice comments, such as “Every reviewer should read this paper.” Overall, the audience agreed with the identified flaws, some of them also noticed these on their own and were happy that someone finally pointed these out. Many were upset about the current state of evaluation in research papers, because they feel it makes papers/results meaningless.
Conference highlights
Based on my experience, RecSys has a two year cycle of stronger and weaker conferences. I’m not sure why it is like this, but it has been fairly consistent throughout the series. In my opinion, even years were the strong ones before 2020 and odd years are the strong ones since then. This year also affirmed this observation as the conference had many high quality presentations and posters. There were also a lot of papers that had their flaws - mostly related to evaluation, sometimes solution design - but introduced ideas I found very interesting nonetheless. This year also holds the record of the most number of papers I reviewed after the conference: 11 long research, 7 short research, 2 reproducibility, 4 industry, 4 from the CONSEQUENCES and 1 from the CARS workshop; 29 in total.
My top paper picks
These are my top paper picks from the conference. This list is entirely subjective and beside the objective quality of the paper, it is based on how relevant it is to my past/current/future work, how much I like the idea, and my feelings on how well I think the idea would work in practice. The following list contains my top picks, without any ordering.
Online Matching: A Real-time Bandit System for Large-scale Recommendations
by Xinyang Yi et al. from Google Deepmind
Very good paper from Google shedding some light on how they do exploration on Youtube. The proposed method is a mix of offline and online training and manages to scale up contextual bandits to Youtube size traffic. There are many good ideas in the paper. The offline part is a two tower model that is responsible for embedding users and items into the same space. Users are then clustered and assigned to their top-W clusters (with cluster weights). Items are associated with clusters based on the similarity between cluster centroids and the item embedding. The bandit algorithm is applied on the top of this many-to-many mapping. To account for the large action space and simultaneous updates, LinUCB is simplified into DiagUCB by using only the diagonal of the covariance matrix. Intuitively, it maintains a bias and a normalization factor, where the latter is always updated with the square of the user’s cluster weight, when there is an impression, while the bias is updated by the reward multiplied by the cluster weight. Updates are only done for corresponding clusters and the item participating in the interaction. The score is computed as the bias multiplied by the user’s cluster weight divided by the normalizing factor. The confidence interval is the sum of the squares of the cluster weights (for the user) divided by the normalizing factor. This means that the more we observe impressions for an item from a cluster, the normalizing factor increases, which results in decreasing the confidence. The bias is increased only if the reward is non-zero, meaning that it quickly diminishes if there are no clicks. Updates are more prominent is the user has a stronger connection to the cluster (and thus to the item). There are also some implementation details in the paper. The online experiments seem to be well designed and they show significant improvements in long term metrics at relatively low short term cost. One interesting thing here is that the bandit runs in exploration and exploitation mode on different parts of the traffic, which seems to be an important aspect of the solution, given the latency of such a large scale system.
Trending Now: Modeling Trend Recommendations
by Hao Ding et al. from Amazon
This paper defines trending score as the acceleration of popularity: popularity is the number of clicks on the item (cumulative), its velocity is the number of clicks under a time unit and trendiness is the change in this velocity under a time unit. The proposed method for predicting this score is a one step time series forecasting based on previous values of the time series and item embeddings. This is done via multitask learning: GRU4Rec is used to learn the next item prediction task, but it is mostly there to learn sensible embeddings and DeepAR is used for time series forecasting using the historical trendiness of the item and its embedding. The paper also defines proper metrics for evaluating how good trend predictions are. They take the top-K predicted items by trendiness and sum up their actual trendiness scores (revealed after the fact). To normalize this score they do min-max normalization using an oracle predictor for the maximal and a random predictor for the minimal value. NDCG can be defined similarly, we just need to discount the values according to the position. The authors also suggest an optimal way for setting the length of the time unit. They assume that there is an optimum, which is a trade-off between variance and bias: short intervals have lower bias, but are very noisy; long intervals have lower variance but can be highly biased. The solution is to look at the performance of a very simple Markov model that always predicts the last revealed trendiness for each item. The optimal interval length is where this model has the best performance. The empirical results suggest that this gives sensible timeframes (e.g. 30 mins for news, few hours of e-commerce, etc.).
InTune: Reinforcement Learning-based Data Pipeline Optimization for Deep Recommendation Models
by Kabir Nagrecha et al. from Netflix
Non-conventional use of RL in this community. The paper argues that the data pipeline is usually the bottleneck in model training, because data needs to be loaded, batched, shuffled and preprocessed on the fly, because caching slightly differently preprocessed training datasets for multiple models would be cost inefficient. These stages can often idle while waiting for the one before them to finish, essentially halting the training process resulting in low GPU utilization. This is worsened by the fact that recsys models are not computationally heavy, thus a forward-backward pass is executed quickly on the GPU. Ideally, each stage would get resources so that they run at the same speed providing a constant flow of data toward model training. There are tools optimizing this, e.g. Tensorflow’s AutoTune, but the authors found that these are not optimal for recsys data pipelines for three reasons: (1) they can’t handle UDFs too well and a significant portion of the recsys pipeline is UDF for data transformation; (2) they crash frequently with OOM (trying to solve the problem by caching a lot of intermediate data and sometimes runs out of memory); (3) they are not able to handle if the pool of available resources changes and they need to reoptimize resource allocation when this happens. The proposed solution is a simple RL model where the reward is throughput*(1-mem/max_mem), the actions are ±0/1/5 CPUs or MBs of memory for each stage independently and the features are simple descriptors, e.g. pipeline latency, model latency, free resources, computer specs, etc. The experiments show that this solution can outperform AutoTune, as well as human tuning and quickly adapts to changing the size of the resource pool.
Optimizing Long-term Value for Auction-Based Recommender Systems via On-Policy Reinforcement Learning
by Ruiyang Xu et al. from Meta
The idea proposed by the paper is to improve a CTR/CVR/bidding model by using on-policy reinforcement learning and biasing the policy towards longer term rewards. Due to business constraints, this is done very gently: the solution is based on one-step improvement, and the new ploicy in linearly combined with the old policy to anchor it to known behavior. A (deep)Q network estimates the state-action values of the base policy and modifies the score given by the CTR/CVR/bid score with the state-action value. Learning the Q values is done via temporal difference learning. There is also some interesting information in the paper on how this can be implemented safely for a critical business task.
Adversarial Collaborative Filtering for Free
by Huiyuan Chen et al. from Visa Research
The paper starts from the BPR-MF model and its adversarial variant ARP. The paper argues that adversarial training makes the model more robust (and accurate), but it is very costly, so they try to simplify that. First, they empirically find that computing the adversarial loss of ARP is enough, but that is still a minmax optimization problem. The paper makes a connection to sharpness-aware minimization. Then they approximate the inner maximization via the first order Taylor expansion of the perturbation and arrive at a loss that needs to minimize the norm of the gradient which would require second order derivatives. Instead, they further approximate this by a trajectory loss and arrive at the final solution of regularizing the scores computed in epoch E to scores computed N epochs before that. This means that they need to store the scores for each example for N epochs, but this seems feasible, even for larger datasets. They also don’t start this regularization until they reach epoch S. The results are promising: the performance of ARP for the training time of BPR. The solution is simple and general, so I think it could potentially work together with many different algorithms and a wide variety of losses. The only concern is whether this score regularization is what really helps the optimizer avoiding sharp minima on the error surface or it works similarly to score regularization in BPR-max, i.e. it doesn’t let scores constantly increase and thus avoids the meaningless item competitions as the consequence of the ranking loss.
There was a very similar paper - titled Enhancing Transformers without Self-supervised Learning: A Loss Landscape Perspective in Sequential Recommendation - by largely the same author group that applies sharpness-aware optimization on transformer based sequential recommenders. The method is the same up to the point where they take the Taylor approximation of the perturbation and define the loss based on minimizing the gradient. At this point this paper proposes an iterative optimization process instead of going for the trajectory loss. This version is less elegant and probably not that efficient (requires two forward/backward passes per minibatch) and the evaluation is flawed (using inappropriate datasets, and there is information leaking through time). But the idea is sound enough that it might be worth looking into.
Other conference highlights
Besides my top picks, I also found interesting ideas in other works presented at the conference.
Keynote of day 3: Recommendation systems: Challenges and Solutions
by Rajeev Rastogi from Amazon
This keynote discussed three challenges and the solutions Amazon used in its production system. These were not necessarily developed by Amazon, but were fit for production use due to being fairly simple ideas that scale well. The first challenge raised was information asymmetry. Item B might be a relevant recommendation to item A, but not vice versa. The solution is to maintain two embeddings for each item: a source and a target embedding. A vanilla graph neural network can be applied over these and predictions can improve if neighborhood sizes are also determined adaptively.
The second problem discussed was delayed feedback. For example, conversion can happen within a few days of the impression, so until the time limit passes, a negative example might be a false negative. Naive solutions either ignore the most recent data or treat false negatives as true negatives. The proposed solution is importance weighting, i.e. the more recent a negative example is, the lower weight it has. These weights can be computed based on how likely it is that the impression will receive a conversion until the time limit is reached.
The third issue was around the uncertainty of predictions. They found that higher uncertainty goes together with lower empirical positivity rate. The solution is to use different thresholds for low, mid and high uncertainty predictions and recalibrate the scores using methods like isotonic regression.
What We Evaluate When We Evaluate Recommender Systems: Understanding Recommender Systems’ Performance Using Item Response Theory
by Yang Liu et al. from University of Helsinki
This paper proposed using item response theory (IRT) for evaluating recommender systems. To put it simply, IRT has tests and test takers. Tests have difficulty, differentiability and guessability (latent) parameters. Test takers have a latent ability to solve tests. These parameters are put into a model and our data (ground truth and predictions) can be used to learn the latent parameters. In the case of recommenders, algorithms are the test takers and ranking tasks are the tests. The intuition is that some of our ranking problems are trivial, some are too hard, but there are some that could really differentiate between models, and these should have larger weights in the evaluation. But this should be computed in a principled way. I like the idea, but there are a few problems with the execution: (1) The authors motivate their work by moving away from ranking@N metrics (recall, mrr, etc.), because they found examples where no algorithm could put the relevant item in the top-N. Instead, they suggest preference estimation over user, preferred item, not preferred item triplets. Training on every possible triplet is not scalable, so the negative item is sampled uniformly to the positive. With realistically sized item catalogs, it is very likely that the sampled item will be a weak negative, so the preference estimation task will be trivial. Negative sampling during testing is also known to be a bad idea. The authors seem to be aware of this, but decided to ignore it. This could be fixed by modifying the tests to be partial ranking@N metrics (e.g. does the algorithm manage to put the relevant item among the top-N). (2) Learning the IRT model takes time. The authors’ implementation takes 8 hours to train on the fairly small Amazon Books dataset. If this is not a code optimization problem, but due to the complexity of the model, then the proposed method won’t be usable in practice. Especially, because it seems that the IRT model needs to be retrained every time we want to compare a different set of algorithms. I wonder if parts of a trained IRT model (e.g. test hardness) could be reused when a new algorithm is added to the comparison, and how sensitive is the test to things like this.
Augmented Negative Sampling for Collaborative Filtering
by Yuhan Zhao et al. from Harbin Engineering University
This is a paper, where (most of) the individual steps seem logical, but the final method could be probably reduced to something much more simple. The paper correctly argues that negative sampling in item based recommenders is a must to ensure scalability. The two main approaches are model-free and model-based sampling. The former uses predefined static distributions (quick, but doesn’t always find strong negatives), the latter uses a sampling model that depends on the state of the trained model (better samples, but very slow). There is also a mix of selecting a larger candidate set in the model-free way and applying the model-based approach on those. The authors identify two problems with these solutions: (1) as the training progresses, finding strong negatives becomes much more difficult, due to their number diminishing; (2) weak negatives might also contain valuable information. The proposed solution (a) decomposes/disentangles the embedding of the negative sample per coordinate using a gating mechanism (how similar it is to the user) into strong and weak parts; (b) augments the weak part of the embedding by adding or subtracting a small noise from it (the magnitude of the noise depends on how similar the positive and negative embeddings are); (c) samples from these virtual negative examples based on how similar they are to the user embedding and based on how similar the augmentation is to the user embedding. The parameters of this sampling model are learned along with the base model. Looking at the solution in more detail reveals that basically what it does is that it slightly increases the value of coordinates where the negative embedding is smaller than the positive and decreases it where it is smaller. It is likely that the gating, disentangling, etc. parts don’t really do anything, and what really matters is how do we set the magnitude of the perturbation. This assumption is also supported by the authors’ ablation study in the paper. The proposed way of setting the magnitude also seems problematic: it is around 0.5 if the positive and negative embeddings are correlated positively or negatively and either 0 or 1 if they are uncorrelated (depending on the sign). It is probably better to use a hyperparameter instead.
gSASRec: Reducing Overconfidence in Sequential Recommendation Trained with Negative Sampling
by Aleksandr Petrov and Craig Macdonald from University of Glasgow
This paper received the “best paper” award of the conference. It is important in the sense that it highlights serious flaws in two popular sequential recommender algorithms, SASRec and BERT4Rec that are direct applications of self attention and BERT without significant tailoring towards the recommendations domain.
The gSASRec paper identifies that BERT4Rec doesn’t do negative sampling during training that makes it not scalable and SASRec uses the binary cross-entropy loss over positive-negative pairs. The authors argue that the problem with this loss is that it can produce an overconfident model that often predicts scores close to 1, even for negative items, which can destabilize the loss during training. This is more likely to happen if more negative samples are used, which would be desirable to improve performance. The proposed solution is the gBCE loss, which basically scales the gradient of the positive item by beta (<1) and under some strict assumptions (no local minima & uniform negative sampling only) it makes the model converge to the true probabilities. There are a few issues with the paper. (1) Overconfidence analysis of the sampled softmax loss doesn’t seem right (even though this is not the focus). (2) The main problem with BCE in this case is not overconfidence, but that it has a trivial solution (especially if there are many negative samples) which seems to be worsened by the gBCE extension. (3) The evaluation is flawed (non-sequential data, non time based split).
SPARE: Shortest Path Global Item Relations for Efficient Session-based Recommendation
by Andreas Peintner et al. from University of Innsbruck
The paper proposes a graph neural network (GNN) based solution for session-based recommendations. Contrary to previous work it tries to keep the architecture as simple as possible (a single graph convolution layer), but compensates for it by basically augmenting the data. First, they search for shortest paths in the global session graph and add edges between two items if the cost of the shortest path between them is under a threshold. Second, an auxiliary task is learned simultaneously with the next item prediction task. This “supervised contrasive learning” task moves the embeddings of positive items together while also moves them aways from the embeddings of negative items. In this case, positive items are coming from sessions that have the same target as the current session and they are the items directly before this target. Negative items are the target items of sessions that are similar to the current session (based on BLEU score) but have different targets. Evaluation is probably ok. The only downside is that while the authors claim that this model is both more accurate and faster to train than competing GNN methods, a single epoch on the small RetailRocket dataset still requires 10+ minutes. In comparison, GRU4Rec only takes 2.9 seconds. The reason for the slow training speed can be the implementation and/or the algorithm itself. It is worrying that both the shortest path search and session similarity computations could scale poorly. On the other hand, these could be precomputed and used throughout the whole training resulting in a constant overhead that is independent of how many epochs are used. However, this constant overhead could still scale poorly with the size of the data (e.g. session similarity computation between every pair of sessions).
Data-free Knowledge Distillation for Reusing Recommendation Models
by Cheng Wang et al. from Huazhong University of Science and Technology and Huawei
This paper argues that we train our models for a long time using expensive hardware, but only use them for a very short amount of time, and this is not cost effective. The proposed solution is to distill the knowledge contained within the model for later use. This is done via model inversion, i.e. fixing the weights, selecting a few outputs at random and using gradient descent to optimize the input of the model (starting from uniform noise) to get synthetic data that contains a fraction of the models knowledge in a compressed form. Since SGD doesn’t work for sparse inputs (directly), the authors propose to learn a continuous input instead of one-hot vectors, which is basically a weighting over the embeddings of every entity indexed by the one-hot vector. They realize that this is not really scalable and cache the weighted embedding for the next forward pass, but for some reason the backward pass updates the whole vector, meaning that there is a dot product between the whole embedding table and a vector, which seems rather expensive. I wonder why they didn’t go for learning the weighted embedding directly. Sparsity is not the only issue to overcome, because this method can suffer from the generated inputs being too similar, which means that they cover only a small portion of the model’s knowledge. The authors use two tricks to fight this: (1) at some point during the process they also freeze every input except for one and alternate; (2) they regularize layer activations to the running mean and variance collected by batch-normalization. Their experiments suggest that two magnitudes less synthetic data is enough to achieve the same accuracy than what was used to train the original model. However, the combination of the synthetic and newly logged data is probably not trivial, especially if a synthetic data point contains much more information.
On the Consistency of Average Embeddings for Item Recommendation
by Walid Bendad et al. from Deezer and Universite Paris
Averaging embeddings to represent an entity composed of other entities (e.g. user represented by the items they visited) is a common practice. This paper asks the question whether it is a good idea. The main contribution of the paper is the definition of average embedding consistency. This can be computed for a given K number as the mean of precisions; and the precision is the intersection of a set of K embeddings and the K embeddings nearest to their average, divided by K. The paper then examines how consistent averaged embeddings are given K and the total number of embeddings both for synthetic and real-life embeddings and finds that they are fairly consistent in the former case and not consistent at all in the latter. The problem is that it seems that embedding groups are formed randomly in both cases, which is not how they are formed in real life. It would be interesting to check the consistency based on real averaged embeddings. In my experience, when a user has multiple interests, their average can be similar to none of them (at least in the case of averaging similarities). Therefore, I can partially believe the results of the paper, but my intuition is that the majority of averages are based on fairly homogeneous groups (or at least somewhat related items), thus consistency should be a given. Also, consistency is probably dependent on how embeddings are trained. For example, if the model already uses the averaged embeddings for representing something, it would probably result in much more consistent averages than averaging pretrained embeddings after the fact.
Efficient Data Representation Learning in Google-scale Systems
by Derek Zhiyuan Cheng et al. from Google Deepmind
This paper is the summary of two other Google papers published earlier. The first one is about an efficient solution for storing embeddings. The embedding for every type of entity (users, items, categories, etc.) are stored in a single table and each entity can point at one or more rows of this table, but no two entities of the same type should point at the same row. Entities of different types can (and should) collide. The idea is that with this many-to-many embedding mapping, the embedding records are reusable as they simultaneously represent entities of different types. Projections in the model can compensate for the collisions. Another good thing about this approach is that it allows for a (limited) variance in the dimensions for different types as the number of rows an entity is pointing at can be different per category. The second paper is about the deep cross v2 architecture that is an architecture to learn high order feature interactions by applying so called cross-layers. A cross layer is the elementwise product of the embedding vector and a linearly mapped output of the previous cross layer, plus the output of the previous cross layer added to this sum. Applying this layer N times can model N-order feature interactions.
Leveraging Large Language Models for Sequential Recommendation
by Jesse Harte et al. from Delivery Hero
One of the applications of LLMs from the conference. The paper proposes three options for using LLMs for sequential recommendations. (1) Average item embeddings extracted from the LLM (based on the title of the item) to model the sequence and recommend the most similar items. (2) Prompt the model to complete the sequence of items. The title imagined by the LLM probably won’t match any existing item. If that is the case, simply find the closest title to this virtual item. (3) Initialize sequential models from item embeddings extracted from the LLM. They use PCA to reduce the dimensionality of the embedding to a manageable size. The evaluation in the paper is not great, one of the datasets is non-sequential, the other is a new dataset they’ve just made public. Assuming that this latter exhibits sequential patterns, it is clear that option (1) is not good. Option (2) won’t work in practice due to the time required for the LLM to complete the sequence is too slow for inference. Option (3) seems to have worked for them, but I’m still somewhat skeptical based on our earlier experiments with initializing session-based models from metadata based embeddings. We found that if these embeddings are fixed, the model is not accurate and if these embeddings can be fine-tuned by the model then they become very similar to event based embeddings and no trace of the metadata will be left in them. However, those experiments used averaged word embeddings for item representation, so maybe the more advanced embeddings coming from LLMs could behave differently.
Scaling Session-Based Transformer Recommendations using Optimized Negative Sampling and Loss Functions
by Timo Wilm et al. from OTTO
This paper was interesting to me for two reasons. First, they published a new, realistically sized dataset that can be used for evaluating session-based recommenders. Second, they added a few of the adaptations from GRU4Rec to SASRec and found that those could improve SASRec too. (Recall that GRU4Rec if GRU adapted heavily to the recommendations domain and SASRec is more or less a direct application of self attention on recsys data.) While this is not surprising to me, it is good to see that parts of the community start to realize the shortcomings of the direct application NLP methods to recommenders, and experiment with adaptations instead, some of which were proposed in earlier work. One issue with the paper is that we confirmed in person that the GRU4Rec implementation - while better than the public implementations we examined - is not perfect as a few features/parameters are missing. There are also a few problems around code optimization, because the training speed reported on the poster is far below what the official implementation can achieve.
Workshop days
The two days preceding the main conference offered 18 workshops and 6 tutorials, as well as the doctoral symposium. Most of the tutorials fit into a single session (~1.5 hours), while workshops were either half day (2 sessions) or full day (4 sessions). It is good to see that while a few of these workshops, like IntRS or CARS, have been around for more than a decade now, they can still maintain a stable audience.
CARS
The CARS workshop has been around for a while, the website says that it was organized yearly between 2009 and 2012, and then it was restarted from 2019 after a long hiatus. I selected this workshop to be my Monday afternoon program, because of the fond memories I have of context-aware recommenders from my PhD research, and because I was interested if there was substantial progress in this field during the last 5-7 years.
The workshop was well organized and it had a decent program with 2 keynotes and 5 papers. The two keynotes actually covered main conference papers in an extended form. Not that I really mind, but I found it odd that this time the selected papers were presented officially after the workshop days but during the same conference. Even though, it is not strange if a workshop recycles papers already presented at other conferences as either keynotes or even as regular presentations.
My highlight from this event was the paper titled Weighted Tensor Decompositions for Context-aware Collaborative Filtering by Joey De Pauw and Bart Goethals. Just as I adapted two tensor decomposition methods for implicit feedback based context-aware recommendations using ALS and weighted RMSE loss, resulting in iTALS and iTALSx, so did they adapt another one - tensor train factorization - resulting in WTF (Weighted Tensor Factorization). In this decomposition, the context is not represented by a feature vector, but by a matrix. This makes the model more expressive, but computing this matrix makes the method scale worse (from \(k^3\) to \(k^6\)). The scaling might not be that bad in practice for reasonable latent dimension size, because the cardinality of context is usually low, thus the \(k^2\) part of the training time should dominate the expression in most cases. This part of the paper was interesting to me mostly due to nostalgia, but there is also an idea in the paper that I really like. The authors propose to regularize the representation of the context to a value that results in the context not influencing the prediction. This is a vector of ones for iTALS, a vector of zeros for iTALSx and the identity matrix for WTF. The reasoning behind this is that if the context is not informative it shouldn’t affect the predictions either. Regularizing towards zero in models like iTALS would only diminish the scores, which is not what we really want. In fact, it seems that this idea also fixes the sharp accuracy loss of iTALS with many context dimensions, especially if one or many of the context dimensions are weak. Now I really wonder how this relates to the interaction model from GFF: do they basically do the same thing or can they stack? The idea behind the interaction model is to compute the prediction as the sum of the pure user-item relation and the user-item relation reweighted with each context dimension separately. Seemingly a very different idea, but the motivation is the same: if the context has no effect on the prediction, the model can still rely on the pure user-item relation. We can also write the interaction model as \(1^T(U\circ(1+C1+C2+...)\circ I)\) with all vectors regularized towards zero, which is the same as regularizing the context vector towards one if there is only a single context dimension. But the two models start to diverge if there are more than one context dimensions.
CONSEQUENCES
In my mind, this workshop is the “spiritual successor” of the REVEAL workshop. It focuses more on counterfactuals and less on reinforcement learning, but there is a significant overlap between the topics, presenters and the audience of the two workshops. Last year, both of them were organized as a joint two day event (mini conference). This year it was CONSEQUENCES only.
Similarly to last year’s CONSEQUENCE (and to previous REVEAL) workshop, the program of this full day workshop was a good one. The organizers chose to go for a full day event, which means that they had to fill four ~1.5 hours long sessions. Each of the sessions started with a keynote or tutorial and then one or two paper presentations. If you are interested in this topic, I suggest watching the recording which is available from the workshop’s website.
My favorite presentation was Minmin Chen’s keynote about exploration in recommender systems. This talk summarized the high quality work she and her colleagues have been doing for the last few years on exploration in the Youtube recommender, including measuring its value, building a dedicated stack for it, designing algorithms for exploration, and more. The talk is full of interesting ideas and observations. In my opinion, it is clearly worth (re)watching.
I also really liked Michael Jordan’s keynote on statistical contract theory and its connection to recommenders. This topic is not something that you can frequently encounter in our research space and I found it interesting. I’ve always thought that it is a good idea to allocate some of the keynotes to topics that are connected to the conference, but different from what the majority of the audience is dealing with on a daily basis and from the majority of the presentations at the conference.
My paper highlight of this workshop goes to Double Clipping: Less-Biased Variance Reduction in Off-Policy Evaluation by Jan Malte Lichtenberg et al. from Amazon, because I find the idea very creative. Inverse propensity scoring (IPS) is unbiased, but has a huge variance. One of the ways to reduce variance is to clip large weights (CIPS). This reduces variance at the cost of introducing bias. This bias is always negative, thus adding positive bias would make CIPS less biased. Sticking with weight clipping, the paper suggests clipping small weights as well. This adds another bias, which is always positive. The bias from clipping large and small weights counteract each other making the proposed dCIPS less biased than CIPS. The negative bias is observed on examples where the weight is big, while the positive bias is introduced on different examples, where the weight is small. In other words, we are intentionally overestimating the contribution of actions to the reward if they are selected much more frequently by the logging policy than the target policy; in order to compensate for underestimating the contributions of actions that are selected much less frequently by the logging policy. The properties of the proposed method are demonstrated on simulated data. While I like the idea, I wonder how and why this really works (and even if it truly works on real data). I’m also curious about how to set the clipping thresholds and how different configurations favor different policies based on how they deviate from the logging policy.
An observation I made during the workshop is that counterfactual evaluation related papers are evaluated almost exclusively on simulated data with a small action spaces. To me this suggests that counterfactual evaluation and learning for recommender systems is still in the lab and doesn’t work well on the scale of real recommenders. There have been a few counter examples five years ago (Recap, Offline A/B testing, etc.), where the paper suggests that the proposed method is used in production or in production adjacent environments. But for me, this makes the almost exclusive use of simulated data this year even more strange.
Closing thoughts
Overall, I really enjoyed RecSys 2023. I have a general positive bias towards this conference, because this is the event where I meet up with colleagues and acquaintances from the industry and academia. But I think that we can safely say that this year it was an objectively good conference: it was both well organized and had a strong program. I was also satisfied with how our presentations went and how our papers were received by the community. Next year, the conference will be in Bari, Italy, which is much closer to us than Singapore, so we might even be able to go with a biggert team. We’ll see. I also hope that 2024 will be the year when RecSys breaks my observation on the two year cycle and we will have two (and then more) subsequent RecSys conferences with very strong programs.